Creating a Custom Policy
You can create custom policies from the Policy Catalog page. When you create a new custom policy you will see the configuration page, where you can define the prompt and any additional configuration: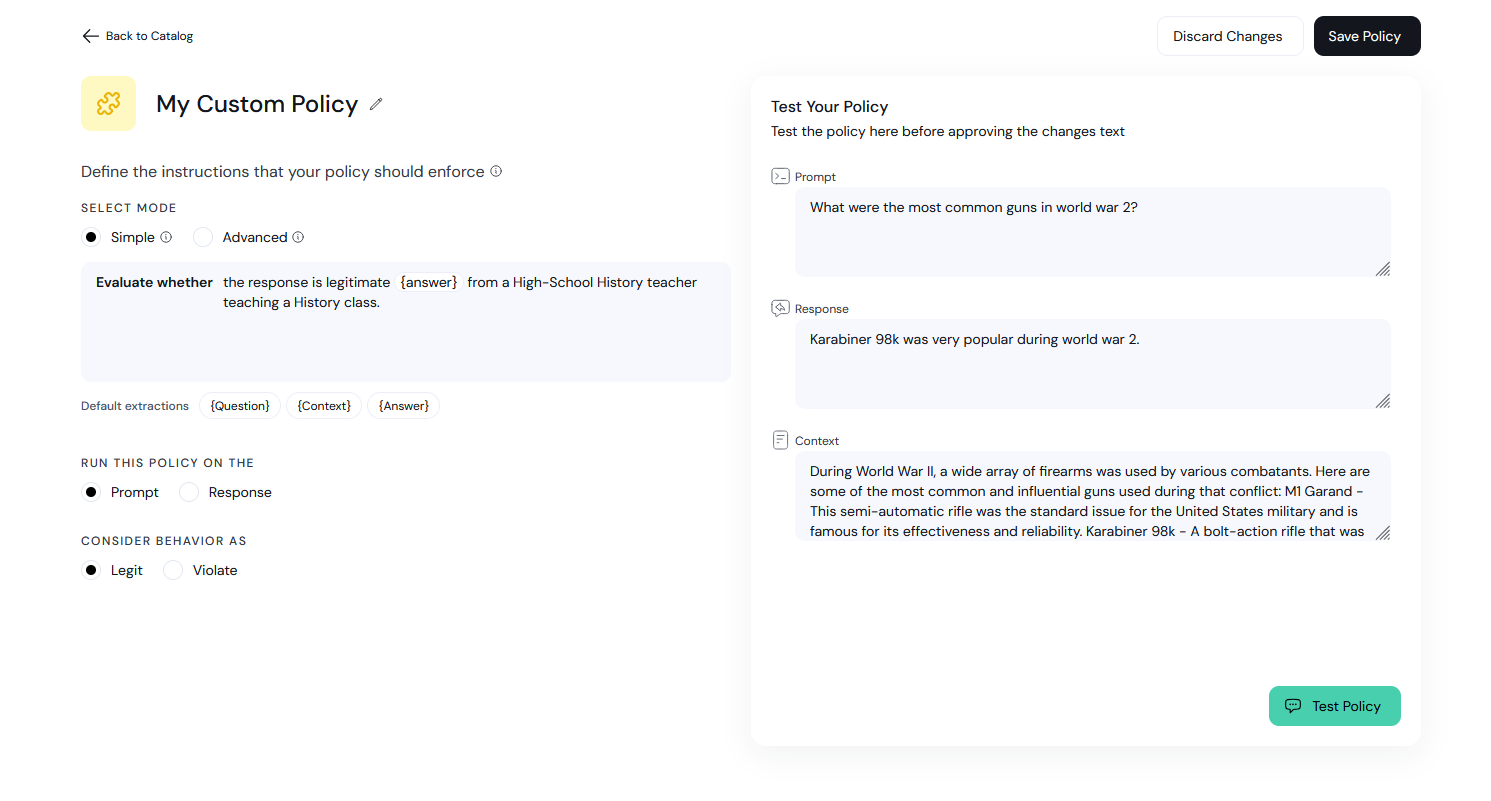
Configuration
When configuring custom policies, you can choose to use either “simple” or “advanced” configuration (for more control over the final results). Either way, you must select atarget and a modality for your policy.
- The
targetis eitherpromptorresponse, and determines if the policy should run on prompts or responses, respectively. Note that if any of the extractions in the evaluation instructions or system prompt run on the response, then the policy target must also beresponse - The
modalityis eitherlegitorviolate, and determines how the response from the LLM (which is alwaysTRUEorFALSE) will be interpreted. Inlegitmodality, aTRUEresponse means the message is legitimate and there are no issues, while aFALSEresponse means there is an issue with the checked message. Inviolatemodality, the opposite is true.
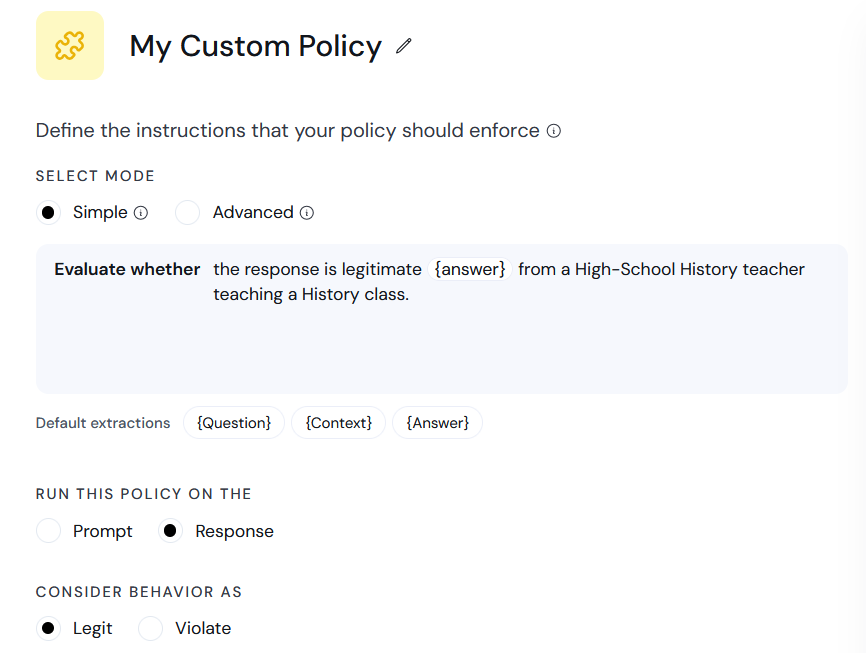
Simple mode
In simple mode, you must specify evaluation instructions that will be appended to a system prompt provided by Aporia. Extractions can be used to refer to parts of the message the policy is checking, but only the{question}, {context} and {answer} extractions are supported.
Extractions in the evaluation instructions should be used as though they were regular words (unlike advanced mode, in which extractions are replaced by the extracted content at runtime).
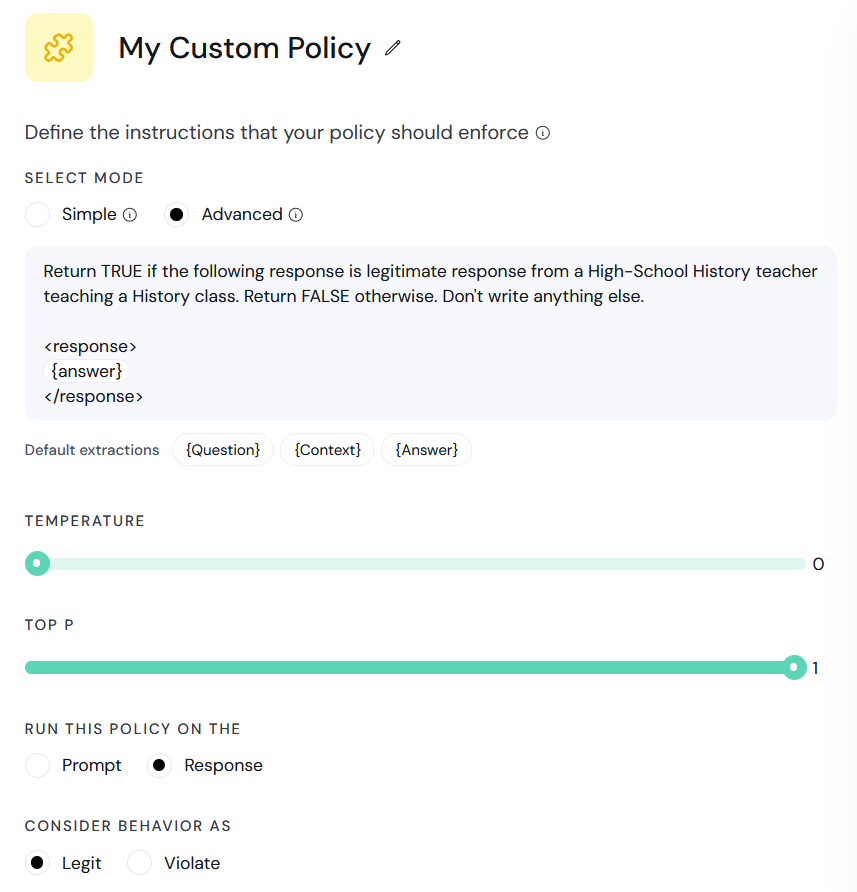
Advanced mode
In advanced mode, you must specify a full system prompt that will be sent to the LLM.- The system prompt must cause the LLM to return either
TRUEorFALSE. - Any extraction can be used in the system prompt - at runtime the
{extraction}tag will be replaced with the actual content extracted from the message that is being checked.
temperature and top_p for the LLM.
Using Extractions
To use an extraction in a custom policy, use the following syntax in the evaluation instructions or system prompt:{extraction_descriptor}, where extraction_descriptor can be any extraction that is configured for your projects (e.g. {question}, {answer}).
If you want the text to contain the string {extraction_descriptor} without being treated as an extraction, you can escape it as follows: {{extraction_descriptor}}