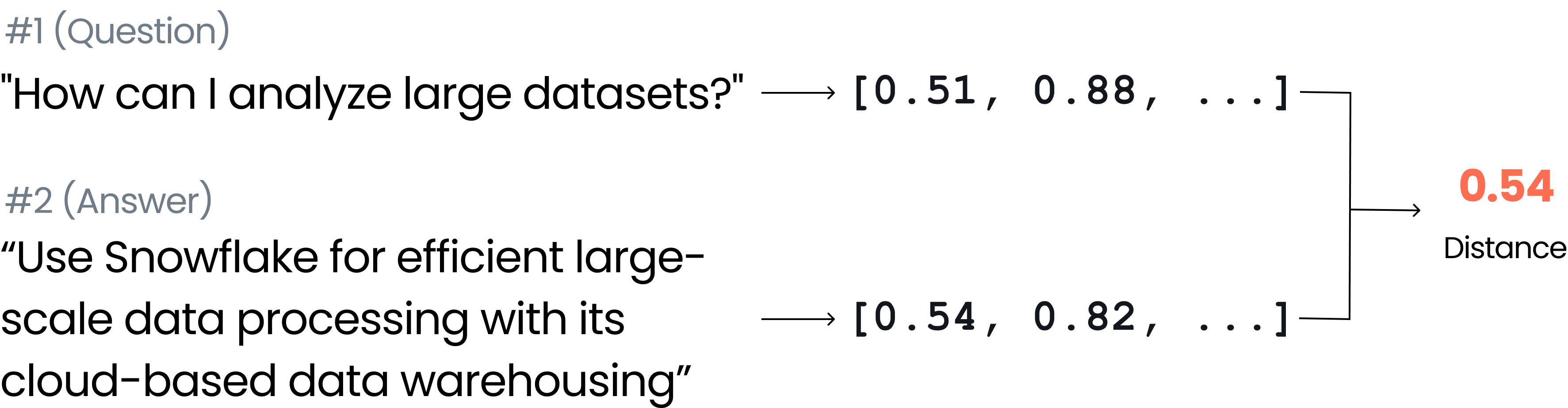Overview
Nobody wants hallucinations or embarrassing responses in their LLM-based apps. So you start adding various guidelines to your prompt:- “Do not mention competitors”
- “Do not give financial advice”
- “Answer only based on the following context: …”
- “If you don’t know the answer, respond with I don’t know”
Why not prompt engineering?
Prompt engineering is great—but as you add more guidelines, your prompt gets longer and more complex, and the LLM’s ability to follow all instructions accurately rapidly degrades. If you care about reliability, prompt engineering is not enough. Aporia transforms in-prompt guidelines to strong independent real-time guardrails, and allows your prompt to stay lean, focused, and therefore more accurate.But doesn’t RAG solve hallucinations?
RAG is a useful method to enrich LLMs with your own data. You still get hallucinations—on your own data. Here’s how it works:- Retrieve the most relevant documents from a knowledge base that can answer the user’s question
- This retrieved knowledge is then added to the prompt—right next to your agent’s task, guidelines, and the user’s question
Specialized RAG Chatbots
LLMs are trained on text scraped from public Internet websites, such as Reddit and Quora. While this works great for general-purpose chatbots like ChatGPT, most enterprise use-cases revolve around more specific tasks or use-cases—like a customer support chatbot for your company. Let’s explore a few key differences between general-purpose and specialized use-cases of LLMs:1. Sticking to a specific task
Specialized chatbots often need to adhere to a specific task, maintain a certain personality, and follow particular guidelines. For example, if you’re building a customer support chatbot, here are a few examples for guidelines you probably want to have:Be friendly, helpful, and exhibit an assistant-like personality
Should not offer any kind of financial advice
Should never engage in sexual or violent discourse
2. Custom knowledge
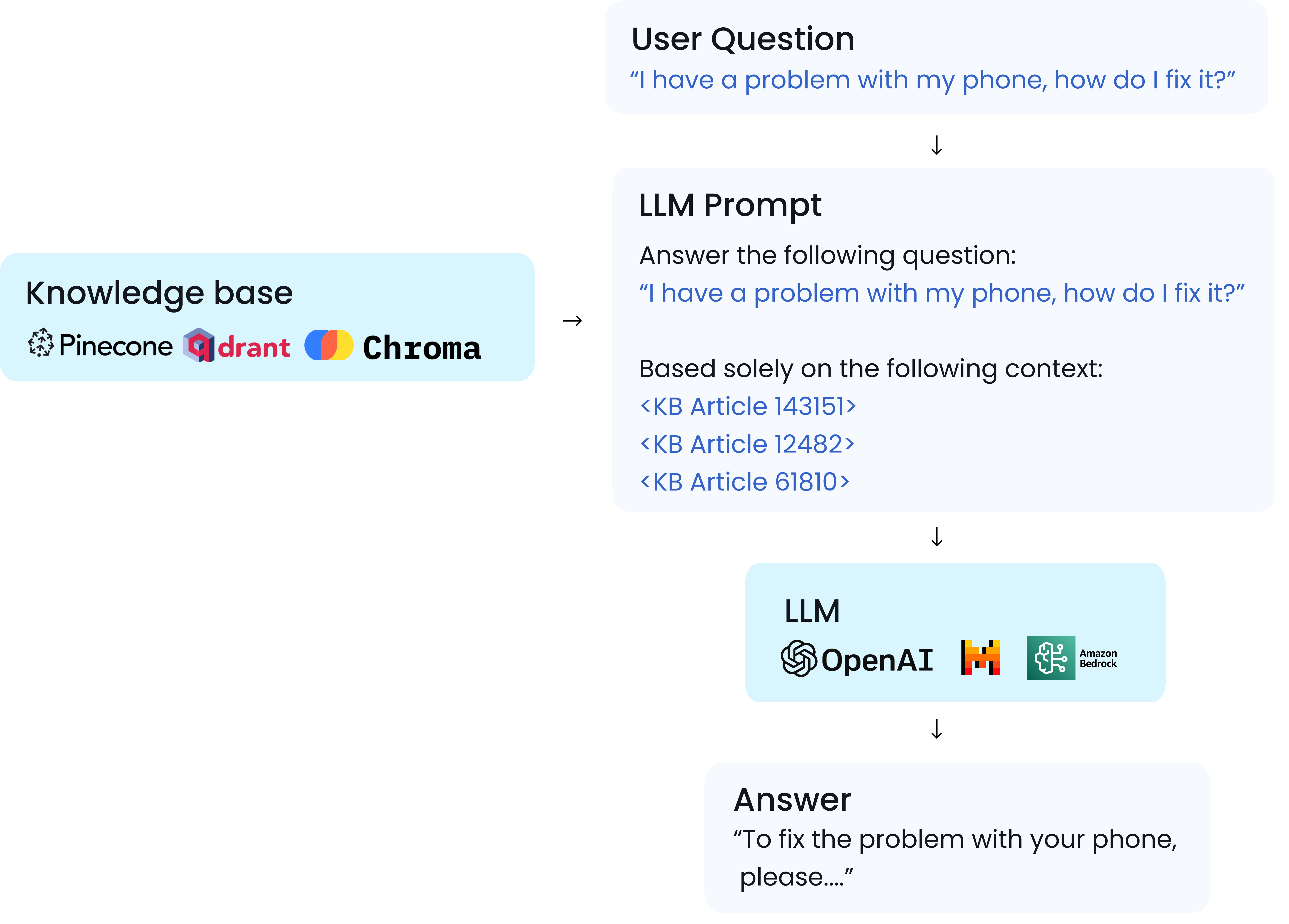
While general-purpose chatbots like ChatGPT provide answers based on their training dataset that was scraped from the Internet, your specialized chatbot needs to be able to respond solely based on your company’s knowledge base. For example, a customer support chatbot needs to respond based on your company’s support KB—ideally, without errors. This is where retrieval-augmented generation (RAG) becomes useful, as it allows you to combine an LLM with external knowledge, making your specialized chatbot knowledgeable about your own data. RAG usually works like this:1
User asks a question
“Hey, how do I create a new ticket?”
2
Retrieve knowledge
The system searches its knowledge base to find relevant information that could potentially answer the question—this is often called context.In our example, the context might be a few articles from the company’s support KB.
3
Construct prompt
After the context is retrieved, we can construct a system prompt:
4
Generate answer
Finally, the prompt is passed to the LLM, which generates an answer. The answer is then displayed to the user.
From Guidelines to Guardrails
We used methods like system prompt instructions and RAG with the hope of making our chatbot adhere to a specific task, have a certain personality, follow our guidelines, and be knowledgeable about our custom data.Problem: LLMs do not follow instructions perfectly
As you can see in the example above, the result of these 2 methods is a single prompt that contains the chatbot’s task, guidelines, and knowledge. While LLMs are improving, they do not follow instructions perfectly. This is especially true when the input prompt gets longer and more complex—e.g. when more guidelines are added, or more documents are retrieved from the knowledge base and used as context.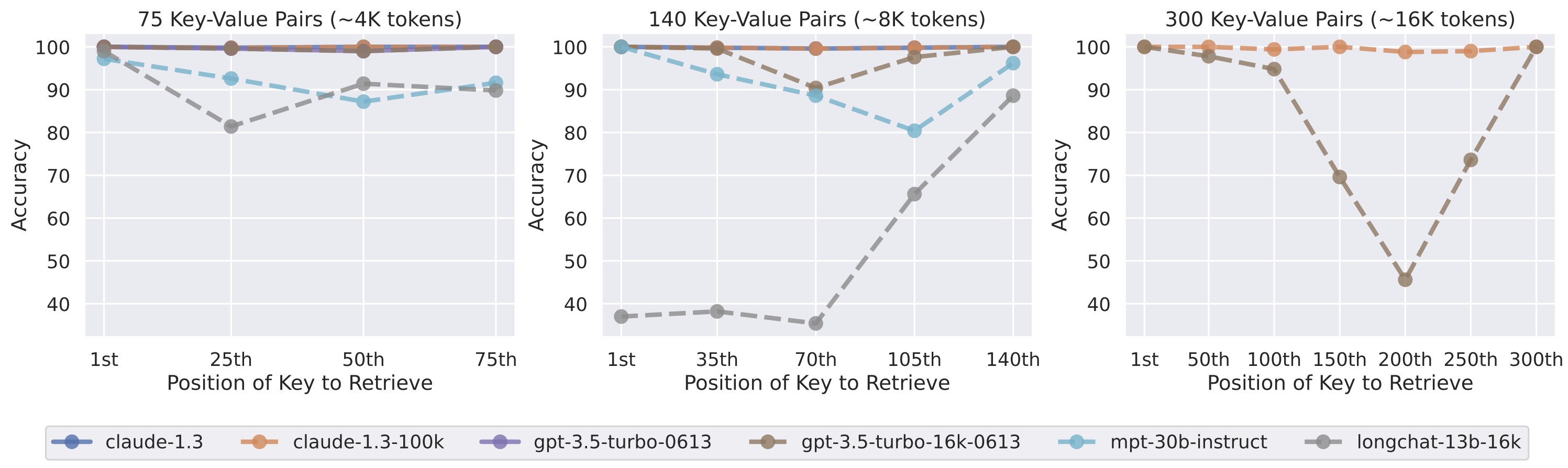
Problem: Knowledge retrieval is hard
Even if the previous problem was 100% solved, knowledge retrieval is typically a very hard problem, and is unrelated to the LLM itself. Who said the context you retrieved can actually accurately answer the user’s question? To understand this issue better, let’s explore how knowledge retrieval in RAG systems typically works. It all starts from your knowledge base: you turn chunks of text from a knowledge base into embedding vectors (numerical representations). When a user asks a question, it’s also converted into an embedding vector. The system then finds text chunks from the knowledge base that are closest to the question’s vector, often using measures like cosine similarity. These close text chunks are used as context to generate an answer. But there’s a core problem with this approach: there’s a hidden assumption here that text chunks close in embedding space to the question contain the right answer. However, this isn’t always true. For example, the question “How old are you?” and the answer “27” might be far apart in embedding space, even though “27” is the correct answer.